
Stephen Medium
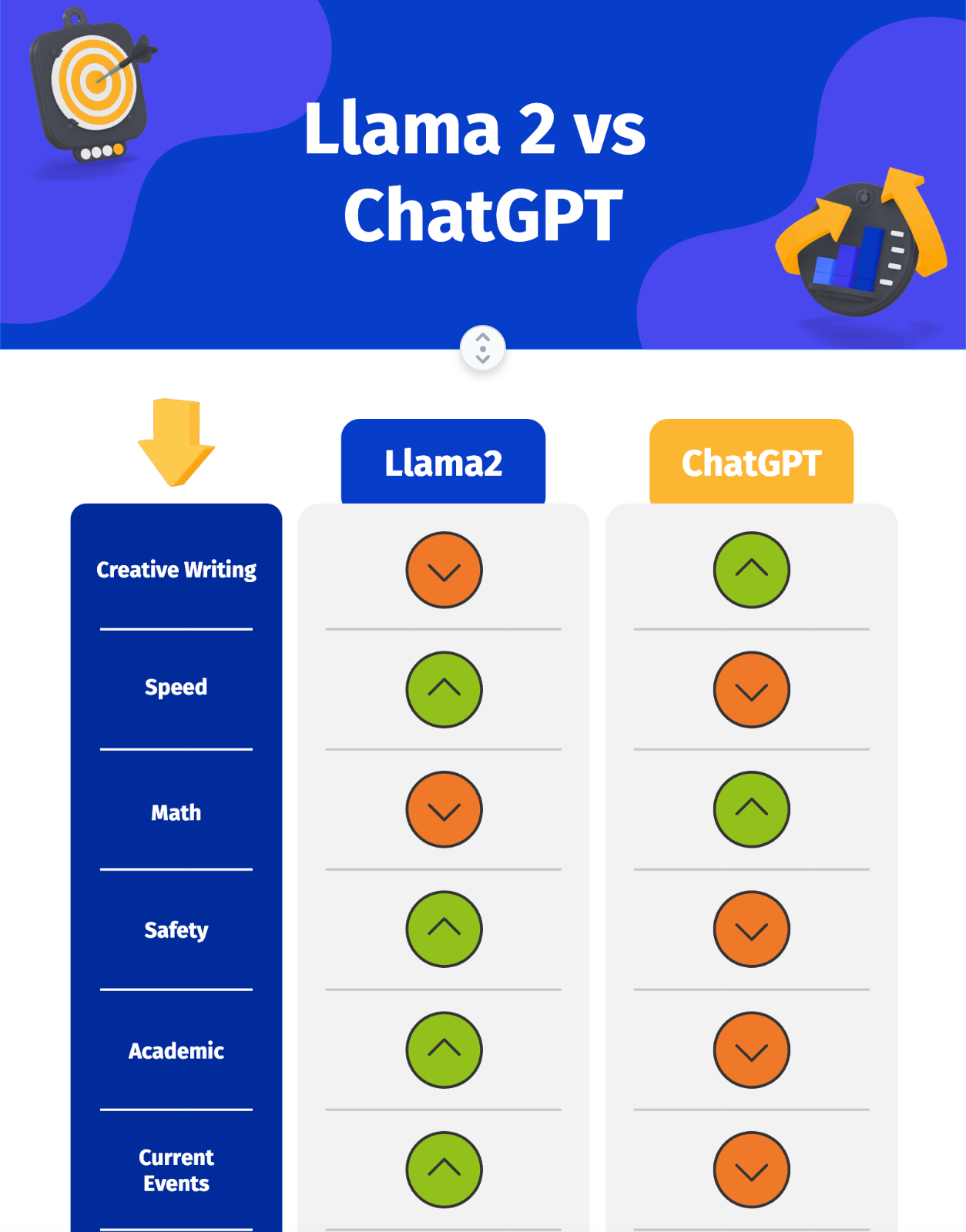
A bigger size of the model isnt always an advantage Sometimes its precisely the opposite. Result Apart from giveaways like this seems to me the main difference is actually not in the model itself but in the generation parameters temperature etc. Result When Llama 2 is not as good as GPT-35 and GPT-4 Llama 2 is a smaller model than GPT-35 and GPT-4 This means that it may not be. Result Llama 2 language model offer more up-to-date data than OpenAIs GPT-35 GPT-35 is more accessible than Llama 2. Result According to Similarweb ChatGPT has received more traffic than Llama2 in the past month with about 25 million daily visits compared to about..
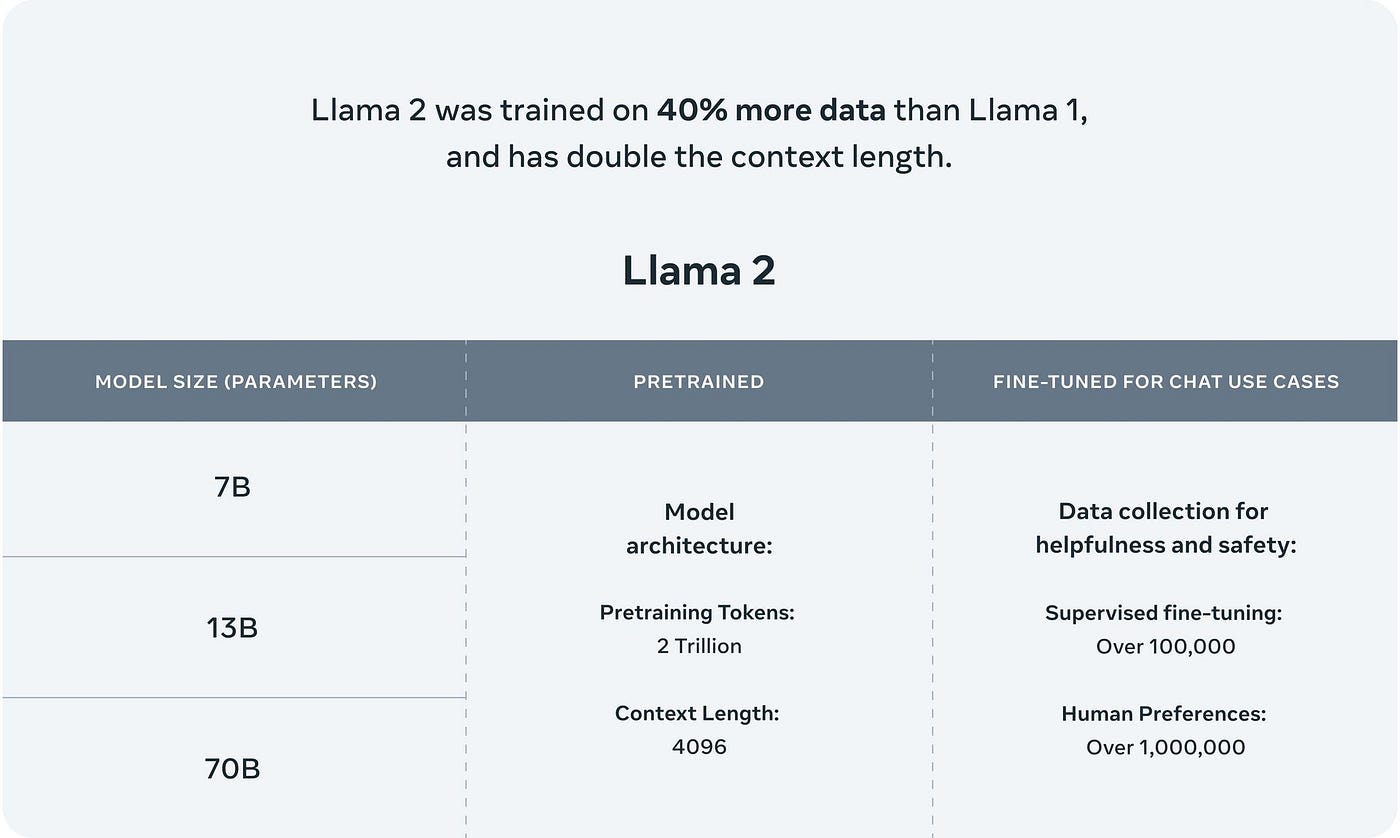
This release includes model weights and starting code for pre-trained and fine-tuned Llama language models ranging from 7B to 70B parameters. Llama 2 is a new technology that carries potential risks with use Testing conducted to date has not and could not cover all scenariosnIn order to. Update Dec 14 2023 We recently released a series of Llama 2 demo apps here These apps show how to run Llama locally in the cloud or on-prem how. We would like to show you a description here but the site wont allow us. Open source free for research and commercial use Were unlocking the power of these large language models..
Stephen Medium
LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM Suitable examples of GPUs for this model include the A100 40GB 2x3090. A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. System could be built for about 9K from scratch with decent specs 1000w PS 2xA6000 96GB VRAM 128gb DDR4 ram AMD 5800X etc Its pricey GPU but 96GB VRAM would be. This repo contains GPTQ model files for Meta Llama 2s Llama 2 70B Multiple GPTQ parameter permutations are provided. With Exllama as the loader and xformers enabled on oobabooga and a 4-bit quantized model llama-70b can run on 2x3090 48GB vram at full 4096 context length and do 7-10ts with the..
Result In this article we will discuss some of the hardware requirements necessary to run LLaMA and Llama-2 locally. Result Llama 2 is an auto-regressive language model built on the transformer architecture Llama 2 functions by taking a sequence of words as input and predicting. Result iakashpaul commented Jul 26 2023 Llama2 7B-Chat on RTX 2070S with bitsandbytes FP4 Ryzen 5 3600 32GB RAM. The performance of an Llama-2 model depends heavily on the hardware its running on. Result Llama 2 The next generation of our open source large language model available for free for research and commercial use..


Comments