
Result In this article we will discuss some of the hardware requirements necessary to run LLaMA and Llama-2 locally. Result Llama 2 is an auto-regressive language model built on the transformer architecture Llama 2 functions by taking a sequence of words as input and predicting. Result iakashpaul commented Jul 26 2023 Llama2 7B-Chat on RTX 2070S with bitsandbytes FP4 Ryzen 5 3600 32GB RAM. The performance of an Llama-2 model depends heavily on the hardware its running on. Result Llama 2 The next generation of our open source large language model available for free for research and commercial use..
Medium
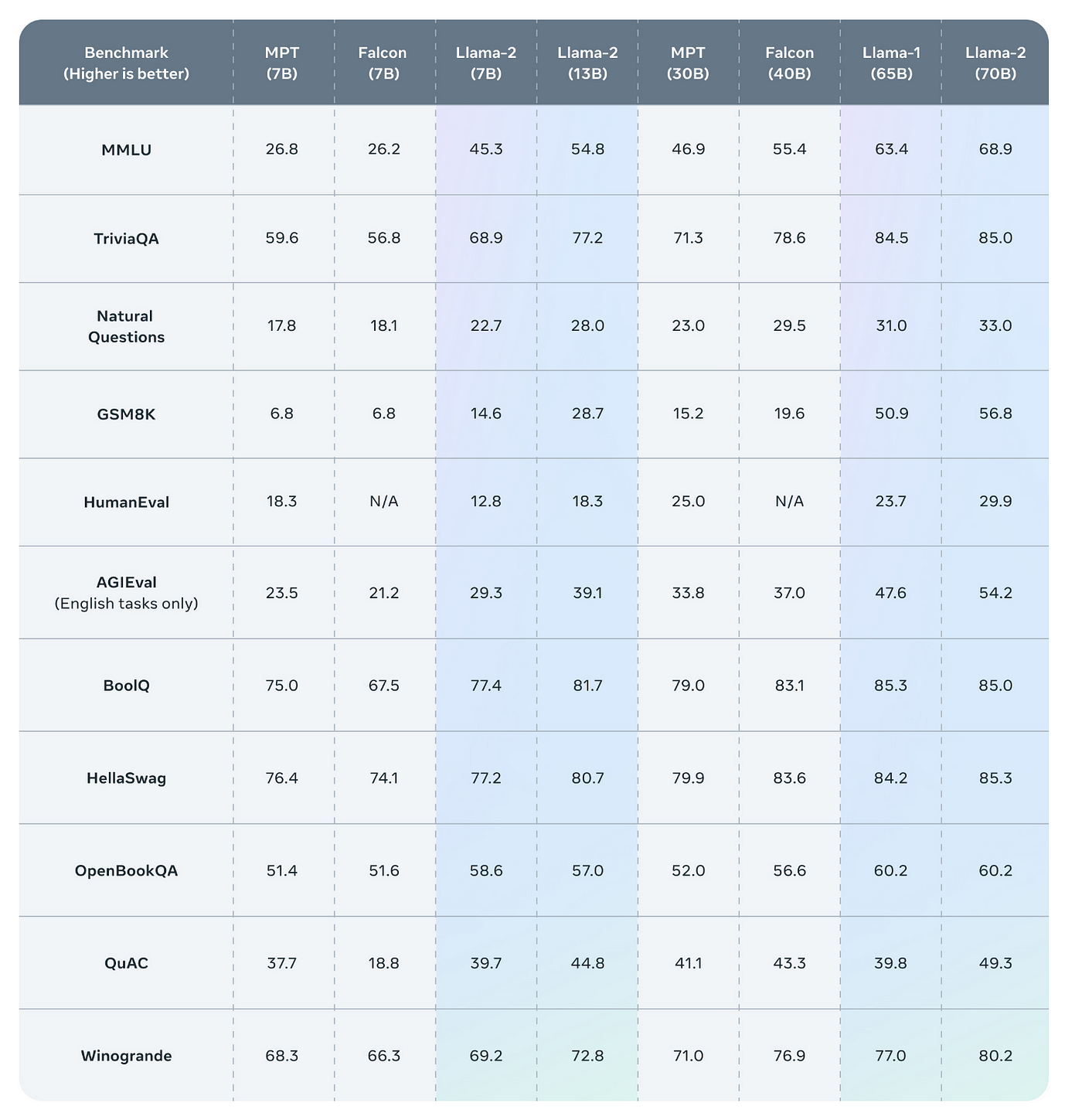
Result All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1. Result LLaMA-2-7B-32K is an open-source long context language model developed by Together fine-tuned from Metas original Llama-2 7B model. Result To run LLaMA-7B effectively it is recommended to have a GPU with a minimum of 6GB VRAM A suitable GPU example for this model is the. Result Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. We extend LLaMA-2-7B to 32K long context using Metas recipe of interpolation and continued pre-training..
The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT and SFT to overcome memory and compute limitations. It shows us how to fine-tune Llama 27B you can learn more about Llama 2 here on a small dataset using a finetuning technique called QLoRA this is done on Google Colab. In this blog post we will discuss how to fine-tune Llama 2 7B pre-trained model using the PEFT library and QLoRa method Well use a custom instructional dataset to build a. In this post we showcase fine-tuning a Llama 2 model using a Parameter-Efficient Fine-Tuning PEFT method and deploy the fine-tuned model on AWS Inferentia2. In this notebook and tutorial we will fine-tune Metas Llama 2 7B Watch the accompanying video walk-through but for Mistral here If youd like to see that notebook instead..

Simform
LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM Suitable examples of GPUs for this model include the A100 40GB 2x3090. A cpu at 45ts for example will probably not run 70b at 1ts More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. System could be built for about 9K from scratch with decent specs 1000w PS 2xA6000 96GB VRAM 128gb DDR4 ram AMD 5800X etc Its pricey GPU but 96GB VRAM would be. This repo contains GPTQ model files for Meta Llama 2s Llama 2 70B Multiple GPTQ parameter permutations are provided. With Exllama as the loader and xformers enabled on oobabooga and a 4-bit quantized model llama-70b can run on 2x3090 48GB vram at full 4096 context length and do 7-10ts with the..


Comments